
ChatGPT, Claude, Gemini, sie alle werben mit immer größeren Kontextfenstern. Claude Opus 4.6 verarbeitet bis zu einer Million Token, Llama 4 Scout meldet sogar zehn Millionen. Das klingt nach: Buch hochladen, Frage stellen, fertig.
Aber ganz so einfach ist es (noch) nicht.
Ich habe in den letzten Monaten viel mit langen Dokumenten gearbeitet, Manuskripte, Recherchen, Sammlungen. Manche Dinge funktionieren erstaunlich gut. Andere scheitern auf eine Weise, die man nicht erwartet. Hier ist, was ich dabei gelernt habe, ergänzt um aktuelle Forschungsergebnisse und Benchmarks.
Inhaltsverzeichnis
Was ist ein Kontextfenster?
Das Kontextfenster ist, vereinfacht gesagt, der Arbeitsspeicher einer KI. Alles, was die KI gleichzeitig sehen kann, deine Frage, hochgeladene Dateien, die bisherige Unterhaltung, muss dort hineinpassen. Was nicht hineinpasst, kann das Modell nicht berücksichtigen.
Gemessen wird in Token. Ein Token ist ein Stück Text, manchmal ein Wort, manchmal nur ein Wortteil. Im Deutschen braucht man für 1.000 Wörter ungefähr 1.300 bis 1.500 Token. Eine Million Token entsprechen also grob 700.000 Wörtern. Das sind ungefähr 1.200 Buchseiten, drei dicke Romane, zwei komplette Jahrgänge einer Wochenzeitung oder ein mittelgroßes Software-Projekt.
Übrigens: Deutsche Texte verbrauchen mehr Token als englische. Das liegt nicht an der Länge unserer Wörter, sondern daran, dass die Tokenizer der meisten Modelle auf Englisch trainiert wurden. Deutsche Komposita und Deklinationen werden deshalb in mehr Einzelteile zerlegt. Das Kontextfenster ist für uns also etwas kleiner als die Hersteller versprechen.
Wie viel passt rein?
Die Zahlen klingen beeindruckend. Claude Opus 4.6 bietet eine Million Token als Standardfenster. GPT-5.4 arbeitet regulär mit 272.000 Token, kann aber über die API auf bis zu eine Million erweitert werden, dann allerdings zum doppelten Preis. Gemini 3.1 Pro liegt ebenfalls bei einer Million, auf der Enterprise-Plattform Vertex AI sogar bei zwei Millionen. Llama 4 Scout von Meta meldet zehn Millionen Token, wobei diese Zahl in der Praxis mit Vorsicht zu genießen ist. Und aus China kommt Alibabas Qwen-Long mit ebenfalls zehn Millionen Token Kontext, gedacht für die Analyse ganzer Dokumentensammlungen (Stand 03/2026).
Wichtig dabei: Die vollen Kontextfenster stehen meistens nur in den Bezahlversionen zur Verfügung, also ChatGPT Plus/Pro, Claude Pro oder Gemini Advanced. Die kostenlosen Varianten arbeiten mit deutlich kleineren Fenstern. Wer große Dokumente verarbeiten will, kommt um ein Abo kaum herum.
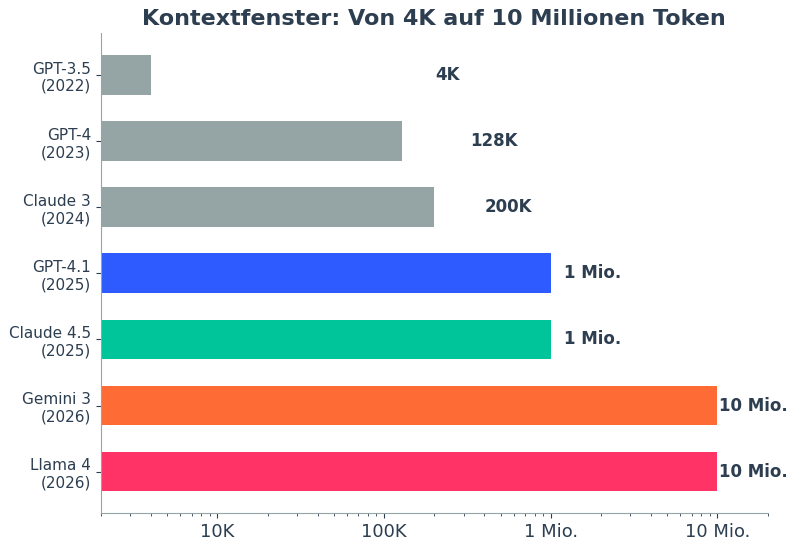
Kontextfenster im Zeitverlauf: von 4.000 Token (2022) bis zu einer Million und mehr (2026). Eigene Darstellung nach Herstellerangaben.
Aber: Die beworbene Kapazität und die nutzbare Qualität sind zwei verschiedene Dinge. In meinen eigenen Tests wurde es bei Claude ab etwa 100 Seiten wacklig, nicht weil das Modell den Text nicht laden konnte, sondern weil die Antworten bei analytischen Fragen zu konkreten Details an Präzision verloren. Die KI hat den Text noch gesehen, aber nicht mehr alles gleich gut verarbeitet.
Das ist kein Einzelfall. Google setzt bei Gemini auf maximale Kapazität, Anthropic dagegen auf Konsistenz, also darauf, dass Claude über den gesamten Text hinweg gleich aufmerksam bleibt. Weniger Platz, aber zuverlässiger. In der Praxis ist das oft der bessere Deal.
Was tatsächlich funktioniert
Trotz der Einschränkungen eröffnen die großen Kontextfenster Möglichkeiten, die es vor zwei Jahren nicht gab.
Ein Buch zusammenfassen. Ein Roman, ein Sachbuch, eine Forschungsarbeit. Hochladen und zusammenfassen lassen funktioniert bei den meisten Modellen gut, solange das Dokument nicht über 200 bis 300 Seiten hinausgeht. Darüber hinaus wird es lückenhaft. Ich habe ein 400-Seiten-Manuskript hochgeladen und nach einem bestimmten Nebenstrang gefragt. Die erste Hälfte wurde sauber erfasst, ab der Mitte fehlten ganze Handlungsteile.
Verträge und juristische Texte prüfen. Anwaltskanzleien lassen KI bereits Vertragswerke auf widersprüchliche Klauseln durchsuchen. Funktioniert, braucht aber immer eine menschliche Endkontrolle.
Code analysieren. Entwickler laden nicht mehr einzelne Dateien hoch, sondern ganze Projekte. Die KI sieht Abhängigkeiten, die tausende Zeilen auseinanderliegen. Das verändert die Art, wie Software entsteht.
Lange Gesprächsverläufe. Wer ein komplexes Projekt über viele Nachrichten hinweg mit der KI bearbeitet, profitiert davon, dass das Modell den Anfang der Unterhaltung noch kennt. Jedenfalls bis zu einem gewissen Punkt.
Das Problem mit der Mitte
Und hier kommt die Ernüchterung. KI-Modelle haben eine Schwäche, die »Lost in the Middle« heißt: Sie gewichten Informationen am Anfang und am Ende eines Textes deutlich stärker als alles, was in der Mitte steht.
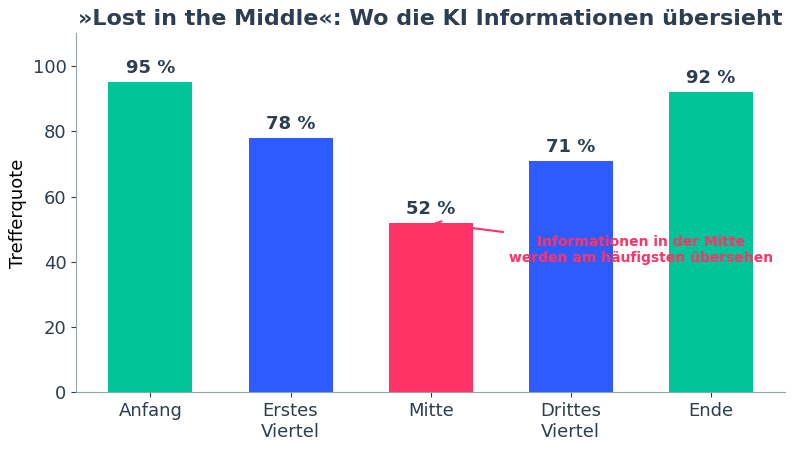
Lost in the Middle: Was am Anfang und Ende steht, wird zuverlässig gefunden. Die Mitte geht oft verloren. Eigene Darstellung nach Liu et al. (2024) und Herstellerbenchmarks.
Das kennt man von sich selbst: In einer langen Liste erinnert man sich an den Anfang und das Ende, die Mitte verschwimmt. Bei KI-Modellen ist der Effekt messbar. Ein Detail, das auf Seite 3 von 200 steht, wird mit hoher Wahrscheinlichkeit gefunden. Dasselbe Detail auf Seite 100, und die Trefferquote kann auf ein Drittel einbrechen.
Der Standardtest dafür heißt »Needle in a Haystack«, Nadel im Heuhaufen. Ein einzelner Fakt wird in einer riesigen Textmenge versteckt, und das Modell muss ihn finden. GPT-5.4 und Gemini 3.1 Pro schaffen das bei reinem Text mit über 99% Trefferquote. Bei anspruchsvolleren Multi-Needle-Tests, in denen mehrere Fakten gleichzeitig gefunden werden müssen, liegt Claude Opus 4.6 laut Anthropics eigenen Benchmarks bei 76% auf einer Million Token (MRCR v2, 8 Needles). Das klingt weniger beeindruckend, ist aber ein Vierfaches dessen, was das Vorgängermodell Sonnet 4.5 schaffte.
Bei Bildern sieht es anders aus. Wer eine PDF mit vielen Grafiken, Tabellen oder Diagrammen hochlädt, muss damit rechnen, dass die KI visuelle Informationen deutlich schlechter verarbeitet als Text. In Benchmarks wie dem MultiModal Needle-Test sinkt die Genauigkeit bei komplexen Bildstrukturen teils auf unter 30%. Die KI übersieht Beschriftungen, verwechselt Daten aus Diagrammen oder ignoriert Abbildungen komplett. Reiner Text bleibt vorerst das zuverlässigere Format.
Was es kostet
Für die meisten Nutzer von ChatGPT, Claude oder Gemini sind die Kosten im Abo-Preis enthalten. Wer aber über die API arbeitet, also als Entwickler oder für automatisierte Prozesse, zahlt pro Token. Und da wird es bei großen Kontexten schnell teuer.
Die Preisunterschiede zwischen den Anbietern sind enorm. Eine Anfrage mit 200.000 Token Kontext kann bei einem Premiummodell wie Claude Opus mehrere Dollar kosten. Bei günstigeren Modellen wie DeepSeek V3 ist dieselbe Menge für einen Bruchteil zu haben. Faktor 20 bis 50 zwischen den Extremen, je nach Anbieter und Modellklasse. Die Preise ändern sich allerdings laufend, meist nach unten.
Ein wichtiger Hebel für API-Nutzer: Prompt Caching. Wer denselben Grundkontext für viele Anfragen nutzt, etwa eine Codebasis oder eine juristische Sammlung, zahlt ab der zweiten Anfrage nur noch einen Bruchteil. Bis zu 90% Ersparnis sind möglich.
Was davon ist für dich relevant?
Wenn du ChatGPT, Claude oder Gemini ganz normal im Chat nutzt, musst du dir über Token-Limits selten Gedanken machen. Die Modelle können heute problemlos ein längeres Dokument, ein PDF oder ein Manuskript verarbeiten. Das ist eine echte Verbesserung gegenüber dem Stand von 2023.
Was du wissen solltest:
Nicht alles auf einmal. Wenn dein Dokument über 100 Seiten hat, arbeite lieber kapitelweise. Die KI liefert bei überschaubaren Abschnitten bessere Ergebnisse als beim Versuch, alles gleichzeitig zu erfassen.
Text schlägt Bild. PDFs mit vielen Grafiken, Tabellen oder eingescannten Seiten sind problematisch. Wenn möglich, lieber reinen Text hochladen oder die KI gezielt auf den Textteil hinweisen.
Wichtiges nach oben. Wenn du der KI ein langes Dokument gibst und eine Frage stellst, stelle die Frage am Anfang oder am Ende. Nicht dazwischen.
Ergebnisse prüfen. Je länger das Dokument, desto höher die Chance, dass die KI Details übersieht oder etwas hinzuerfindet. Bei wichtigen Texten wie Lektorat, Analyse oder Faktenprüfung immer gegenlesen.
Das richtige Modell wählen. Nicht jedes Modell eignet sich gleich gut für lange Texte. Claude gilt als besonders konsistent bei großen Kontexten. Gemini bietet viel Platz und starke multimodale Fähigkeiten. GPT-5.4 ist ein solider Allrounder mit dem größten Ökosystem.
Kein Stress mit Zahlen. Ob ein Modell 200.000 oder eine Million Token fasst, für den Alltag spielt das kaum eine Rolle. Die Qualität der Verarbeitung zählt mehr als die Kapazität. Ein Modell, das 200.000 Token zuverlässig verarbeitet, ist nützlicher als eines, das bei einer Million den Faden verliert.
Und Datenschutz? Ja, die Server stehen überwiegend in den USA. Wer vertrauliche Dokumente hochlädt, sollte sich das überlegen. Allerdings bieten alle großen Anbieter inzwischen Optionen, bei denen hochgeladene Daten nicht fürs Training verwendet werden. Die reflexhafte DSGVO-Panik, mit der in Deutschland jede KI-Nutzung abgewürgt wird, hilft niemandem weiter. Wer sich informiert, kann verantwortungsvoll arbeiten.
Die riesigen Kontextfenster sind eine echte Errungenschaft, aber keine Magie. Sie machen die KI nicht schlauer, sie geben ihr nur mehr zu lesen. Was sie daraus macht, hängt immer noch davon ab, wie gut die Frage ist. (lk)
Quellen und Daten
- IBM – What is a context window?
- Elvex – Context Length Comparison 2026
- Vellum – RAG vs Long Context
- Anthropic – Introducing Claude Opus 4.6
- MMNeedle Benchmark. Modelldaten nach Herstellerangaben (Stand 03/2026)
